不管是 LSTM 還是 RNN,只要時間步太多,就很容易遇到梯度消失的問題——這點我們在 Day 11 也有提過。當資料一路傳到最後一個 context vector 的時候,原本的資訊可能早就已經失真了。這也意味著在 Seq2Seq 模型裡,Encoder 最後輸出的那個 context vector,其實能提供的有用資訊可能很有限。
接著 Decoder 就只能靠這個 context vector 當作初始狀態開始生成文字。但這樣一來就很容易出現一個狀況:模型會逐漸忘記前面的輸入內容,導致產生到後段文字時容易出錯。那要怎麼解決這個問題呢?這就是 Attention(注意力機制)出場的原因了。
當我們講到 Attention 的核心概念其實可以這樣想,Decoder 在每次產生一個字或詞的時候,並不是死板地依賴某一個固定的上下文,而是會根據當下的情境,動態地去「挑選」Encoder 所給的那些資訊裡,哪些比較重要、該多看一點,哪些相對次要、可以少關注。這就像人在聽人講話時會根據對方說的內容有選擇性地去注意某些重點一樣。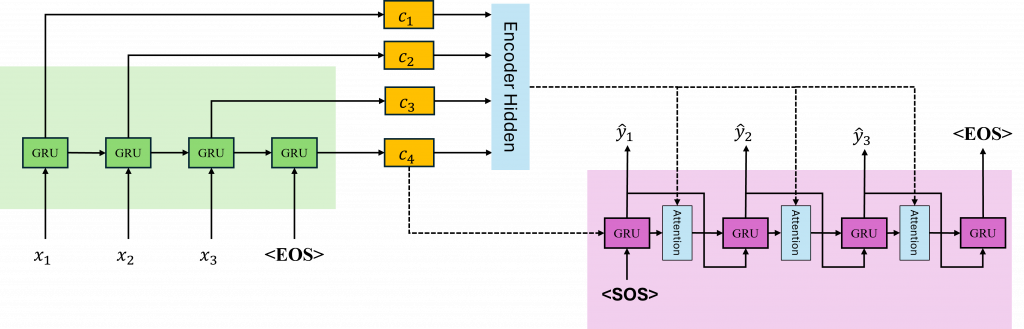
以下為了方便解說我們稱Encoder的輸出為context vector而Deocder則為hidden state。
它的計算方式其實不難理解。基本上就是把 Encoder 目前的context vector ( c(t) ) 和 Decoder 上一個時間點的context vector ( c(t-1) ) 拿來做運算,這個運算可以有很多種做法,比如說直接把兩個向量加在一起、拼接起來,或者互相相乘,在這麼多做法當中,最有名的就是 Bahdanau Attention 這個方式。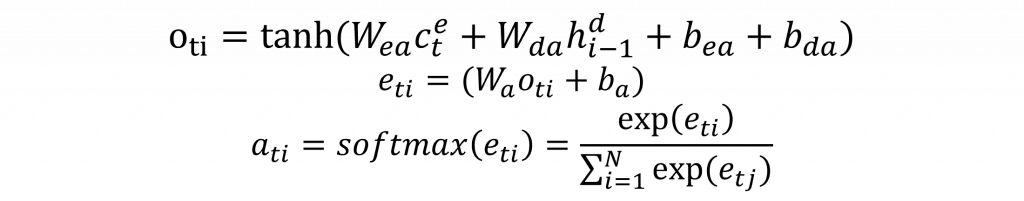
其實這個公式的邏輯不難,簡單講就是把 Encoder 的輸出 ( c(t) ) 跟 Decoder 當下的狀態 ( h(t) ) 拿來湊一湊,變成一個上下文向量。然後這個組合資訊會先丟進一個全連接層,也就是 ( e(t) ),做個線性轉換。接著,再把這些轉換後的結果丟進 Softmax,算出一組機率分布,也就是 Attention Score ( a_t(i) ),這樣一來我們就能得到一個 Attention Weights 的矩陣,也就是每個時間點該注意哪一部分輸入的程度,全部都列出來了。
在程式上我們可以這樣寫要注意的是,Decoder 的 hidden state 通常只有一個,因為我們的模型架構設計是讓 Decoder 根據當下的狀態,去找出 Encoder 裡面最關鍵的 context vector。
class BahdanauAttention(nn.Module):
def __init__(self, hidden_size):
super(BahdanauAttention, self).__init__()
self.encoder_projection = nn.Linear(hidden_size, hidden_size)
self.decoder_projection = nn.Linear(hidden_size, hidden_size)
self.attention_v = nn.Linear(hidden_size, 1)
self.tanh = nn.Tanh()
self.softmax = nn.Softmax(dim=-1)
def forward(self, encoder_hidden, decoder_hidden):
# encoder_hidden: (batch, time, hidden)
# decoder_hidden: (batch, 1, hidden)
energy = self.tanh(self.encoder_projection(encoder_hidden) + self.decoder_projection(decoder_hidden))
scores = self.attention_v(energy) # (batch, time, 1)
scores = scores.squeeze(2).unsqueeze(1) # (batch, 1, time)
attn = self.softmax(scores) # (batch, 1, time)
context = torch.bmm(attn, encoder_hidden) # (batch, 1, hidden)
return context
所以Encoder 的部分會對每個時間步都算出一個 context vector,而 Decoder 則是只關注當下這一刻的 hidden state,來做對應的注意力計算。換句話說Decoder 是根據目前的位置,去決定該把注意力放在哪些 Encoder 的輸出上。
至於 Encoder 的部分寫法其實跟之前差不多,不過這次有個小地方不太一樣,我們這次用的是模型的 output,不是 hidden。為什麼呢?因為 output 會包含每一個時間步的資訊,也就是整個序列的 context vectors,而 hidden 只會給你最後一個時間點的狀態,對注意力機制來說就不夠用了。
class EncoderLSTM(nn.Module):
def __init__(self, vocab_size, hidden_size, padding_idx):
super(EncoderLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=padding_idx)
self.lstm = nn.LSTM(hidden_size, hidden_size, batch_first=True)
self.dropout = nn.Dropout(0.1)
def forward(self, token_ids):
embedded = self.dropout(self.embedding(token_ids))
# embedded: (batch_size, time_step, emb_dim)
output, (h, c) = self.lstm(embedded)
# output: (batch_size, time_step, hidden_size)
# h, c: (1, batch_size, hidden_size)
return output, (h, c)
那在 Decoder 這邊,除了原本輸入的 Embedding 後的 Token,我們還要把 Attention 機制算出來的 context vector 加進來。這兩個向量我們這裡就直接用 concatenate 的方式把它們接起來。
當然啦也可以選擇先用一個 Linear 層來把維度壓縮一下,這樣可以讓模型的 hidden state 不會變太大。不過這種做法沒有一個標準答案,看實作需求而定。我們這裡就先用 cat 來拼接,做法簡單直觀一點。
class DecoderLSTM(nn.Module):
def __init__(self, attention, hidden_size, output_size, padding_idx):
super(DecoderLSTM, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size, padding_idx=padding_idx)
self.lstm = nn.LSTM(2 * hidden_size, hidden_size, batch_first=True)
self.output_projection = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(0.1)
self.attention = attention
def forward(self, encoder_outputs, decoder_hidden, decoder_input_ids):
# decoder_hidden: (h, c), each (1, batch, hidden)
embedded = self.dropout(self.embedding(decoder_input_ids)) # (batch, 1, emb_dim)
h, c = decoder_hidden
decoder_state = h.permute(1, 0, 2) # (batch, 1, hidden)
context = self.attention(encoder_outputs, decoder_state) # (batch, 1, hidden)
lstm_in = torch.cat((embedded, context), dim=-1) # (batch, 1, 2*hidden)
output, (h, c) = self.lstm(lstm_in, (h, c)) # output: (batch, 1, hidden)
logits = self.output_projection(output) # (batch, 1, vocab)
return logits, (h, c)
這兩種做法的差別其實蠻有意思的用 cat 的方式,意思就是我們單純把兩個向量並排起來,讓它們分開保留各自的資訊,沒有做太多加工。
但如果是用 Linear 層來處理,那代表我們想要把這些資訊融合起來,讓模型自己去學哪些特徵比較重要。這時候,通常還會搭配像 tanh 這種非線性函數,來讓輸出變得更平滑、更接近一種平均分佈的 hidden state。
明天我會帶大家實際操作,看看怎麼把這些元件組合起來,完成一個簡單的機器翻譯任務。我也會講解,該怎麼用評估指標來判斷模型生成的結果到底好不好。
這點其實蠻重要的,因為我們不能只看 Loss 值來決定模型表現。Loss 只是模型在訓練資料上的損失,跟實際應用的品質可能不完全對應。實際上,我們要根據任務的需求來選擇適合的評估標準。
比如說,有些任務特別在意準確率,而生成模型又會因為策略(像是 greedy、beam search 或 sampling)不同而產生不同的輸出結果。所以如果我們只看 Loss,是沒辦法全面掌握模型表現的。


 iThome鐵人賽
iThome鐵人賽